In an ideal world, we’d have one person moderating a user research session and at least one other person taking notes or logging data. In practice it often just doesn’t work out that way. The more people I talk to who are doing user research, the more often I hear from experienced people that they’re doing it all: designing the study, recruiting participants, running sessions, taking notes, analyzing the data, and reporting.
I’ve learned a lot from the people I’ve worked with on studies. Two of these lessons are key: Doing note taking well is really hard.
There are ways to make it easier, more efficient, and less stressful.
Today, I’m going to talk about a couple of the techniques I’ve learned over the years (yes, I’ll give credit to those I, um, borrowed from so you can go to the sources) for dealing with stuck participants, sticking to the data you want to report on, and making it easy to see patterns.
Graduated prompting
Say you’re testing a process that has several steps and you want to see the whole thing, end-to-end. This is not realistic. In real life, if someone gets stuck in a process, they’re going to quit and go elsewhere. But you have a test to do. So you have to give hints. Why not turn that into usable data? Track not only where in the user interface people get stuck, but also how much help they need to get unstuck.
This is also an excellent technique for scavenger hunt tasks – you can learn a lot about where the trigger words are not working or where there are too many distractions from the happy path or people are simply going to need more help from the UI.
Here’s what I learned from Tec-Ed about what to do when a participant is stuck but you need them to finish:
- First, ask participants to simply try again.
- If participants are unable to move forward, give a hint about where to look: “I noticed that you seem to be focused mostly in this area (pointing). What if you look elsewhere?”
- If participants are still stuck and want to give up or say they would call someone, let them call a “help desk” or, depending on the study, give a stronger hint without being specific.
- Finally, you may have to get specific.
The idea is to note where in the UI you’re giving the hints and how many for any particular hindrance. This gives you weighted evidence for any given participant and then some great input to design decisions as you look at the data across participants.
Pick lists
You may say this is cheating. But don’t you feel like you have a pretty good idea of what’s going to happen when a participant uses a design? This technique is about anticipating what’s going to happen without projecting to participants what the possibilities are. Make a list of all the possible wrong turns you can imagine. Or at least the ones you care about fixing.
Being able to do this comes from awareness and the researcher’s experience with lots of user interfaces. This is not easy to do if you’ve only done one or two studies. But as you get more observations under your belt, looking ahead gets easier. That is, most of us are paying attention to the happy path as the optimum success in a task, but then have to take lots of notes about any deviation from that path. If you look at what the success and error conditions are as you design a study, you can create list to check off to make data gathering quicker and less taxing as you’re doing both that and moderating.
Here’s an example from a study I did with Ginny Redish researching the language of instructions on ballots. This is on a touch screen, so “touch” is the interaction with the screen, not with an actual candidate:
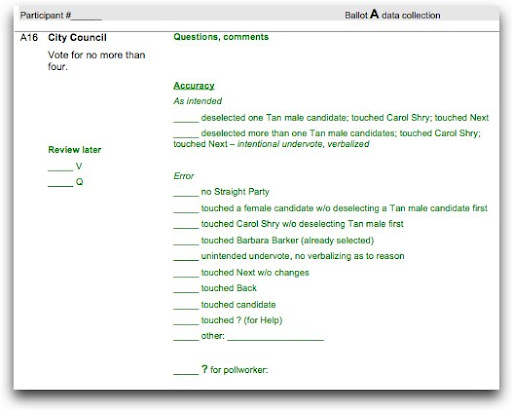
There are a lot of things wrong with this particular example: having the same word at the beginning of many of the possible selections does not make the list easy to skim and scan; there are too many items in the list (we ended up not using all of those error conditions as data points). As we designed the test, we were interested in what voters did. But as we analyzed the data and reported, we realized that what didn’t matter for this test as much as whether they got it right the first time or made mistakes and recovered or made mistakes and never recovered. That would have been a different pick list.

Judged ratings
Usually in a formative or exploratory study, you can get your participants to tell you what you need to know. But sometimes you have to decide what happened from other evidence: how the participant behaved, what they did to solve a problem or move forward, where they pointed to.
As a researcher, as a moderator, you’re making decisions all the time. Is this data? Is it not? Am I going to want to remember this later, or is it not needed?
After we realized that we were just going to make a judgment anyway, Christine Perfetti and I came up with a shortcut for making those kinds of decisions. Really, what we’re doing is assisting judgments that experienced researchers have probably automatized. That is, after dozens or hundreds of observations, you’ve stored away a large library of memories of participant behaviors that act as evidence of particular types of problems.
To make these on-the-fly judgments, Christine and I borrowed a bunch of techniques from Jared Spool at UIE and used variations of them for a study we worked on together. As the moderator of the day asked, “What do you expect to happen when you click on that?” and followed up with, “How close is this to what you expected?” the note taker for the day recorded something like this:
{kind=link}
Another way to use this trick is to ask, “The task is [X]. How close do you feel you are now to getting to where you want to be? Warmer? Cooler?”
I also think that most of us collect too much data. Well, okay, I often do. Then I wonder what to do with it. I’ve found that when I really focus on the research questions, I can boil the data collecting down significantly. So here’s a minimalist note-taking device: I created a one-sheet data collector that covered three tasks and helped me document a pass/fail decision for voting system documentation. You can quibble about some of the labeling in the example below, but I was happy to have one piece of paper that collected what happened along with how I know that, and what that combination of things happening means.
It attempts to encapsulate the observation-inference-theory process all in one place.
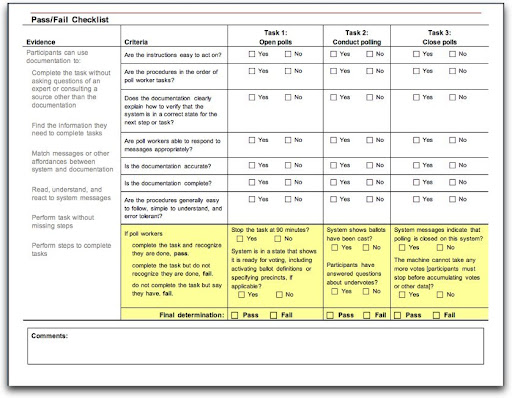
Again, if you haven’t done much user research or usability testing, you may not be happy with this approach. And, let’s not forget how valuable qualitative data like quotes is. But you more experienced people out there may find that codifying the judgments you’re making this way makes it much quicker to note what happened and what it might mean, expediting analysis.
Shortcuts are not for sissies
Most user research is not run in an ideal world. Note taking in user research is one of the most difficult skills to learn. Luckily, I have had great people to work with who shared their secrets for making that part of the research less stressful and more efficient.
Graduated prompting is a way to quantify the hints you give participants when you need them to complete tasks in a process or continue on a path in a scavenger hunt.
Judged ratings are based on observations and evidence that fall into defined success and error criteria.
Got several dozen hours under your research belt? Focus the data collecting. Try these techniques for dealing with stuck participants, sticking to the data you want to report on, and making it easy to see patterns.
Nice post Dana! We mention three other note-taking tips in our Remote Research book, if you happen to be recording your sessions:
1. You can use a special Excel spreadsheet macro or note-taking software to take notes that are automatically time-stamped. That way, you can take rough shorthand notes, and then go back to the recording later to see exactly what was said or done at a specific time.
2. If you want a perfect transcript of a session, you can always hire out an online transcription service like CastingWords.com, though this can be pricey depending how quickly you need it.
3. Some video editing suites like Adobe Premiere are starting to include automatic audio transcription. This will probably be awesome in the future, but right now we've found it to be pretty spotty.
Tony T.
http://boltpeters.com
http://www.rosenfeldmedia.com/books/remote-research/
@Tony T.
Thanks for the adds! Cool ideas.
Glad you liked the post, too.
Dana
dana AT usabilityworks DOT net
Thanks for your post, Dana. It provided some good validation to my methods.
I generally follow a 3 strike approach to prompting:
1. Repeat the question verbatim
2. Provide generalized guidance (without telling participant where to go, what to do)
3. If next task stems from completion of current one, then I will give them the answer and mark the task as not successfully completed.
I too have the “What do expect will happen when you click…?” and “Did that meet your expectation?” questions in my arsenal. I've found them to be very helpful, but my latter question is not scaled. I use a why/why not to have them explain why it met or did not meet expectation for behavior. So, how has the scale helped?
Hi Dana! Great tips.
You may like this article from Website Magazine that reviews usability tools http://bit.ly/32mqlQ
I am affiliated with http://www.usertesting.com but the article covers several others.
Amanda